
Rust 基础入门(二)(已完结)
本文为阅读《Rust圣经》的第二篇笔记,内容包括《Rust基础入门》5~7章节,阅读本文前建议先阅读本网站的文章《Rust基础入门(一)》,后续章节请移步到本网站文章《Rust基础入门(三)》等,如果想查看原书请搜索“Rust圣经”或点击此链接:[Rust语言圣经(Rust Course)](https://course.rs/about-book.html)
流程控制
if 分支控制
和大多数编程语言非常类似,Rust 也由 if 语句控制分支
1 | if condition == true { |
if 语句块可以作为语句,也可以作为表达式,例如下面两个代码等效:
1 | /* 1 */ |
注意:若 if 语句块是表达式,那返回类型要一致。
else if 处理多重条件
例:
1 | fn main() { |
for 循环
for 循环基本用法
1 | for 元素 in 集合 { |
注意,使用 for 时我们往往使用集合的引用形式,除非你不想在后面的代码中继续使用该集合(比如我们这里使用了 container 的引用)。如果不使用引用的话,所有权会被转移(move)到 for 语句块中,后面就无法再使用这个集合了)。
但是:对于实现了 copy 特征的数组(例如 [i32; 10])而言, for item in arr 并不会把 arr 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 arr 。
如果想在循环中,修改该元素,可以使用 mut 关键字:
1 | for item in &mut collection { |
循环变量也可以简化为 _ ,这样可以不用单独声明一个变量:
1 | for _ in 0..10 { |
for 循环的两种循环方式
1 | // 第一种 |
第一种方式是循环索引,然后通过索引下标去访问集合,第二种方式是直接循环集合中的元素,优劣如下:
- 性能:第一种使用方式中 collection[index] 的索引访问,会因为边界检查(Bounds Checking)导致运行时的性能损耗 —— Rust 会检查并确认 index 是否落在集合内,但是第二种直接迭代的方式就不会触发这种检查,因为编译器会在编译时就完成分析并证明这种访问是合法的
- 安全:第一种方式里对 collection 的索引访问是非连续的,存在一定可能性在两次访问之间,collection 发生了变化,导致脏数据产生。而第二种直接迭代的方式是连续访问,因此不存在这种风险( 由于所有权限制,在访问过程中,数据并不会发生变化)。
continue
使用 continue 可以跳过当前当次的循环,开始下次的循环
break
使用 break 可以直接跳出当前整个循环
while 循环
while 循环基本用法
1 | fn main() { |
为什么说 for 安全性优于 while ?
以下两代码作用相同,但是 for 并不会使用索引去访问数组,因此更安全也更简洁,同时避免运行时的边界检查,性能更高。
1 | /* while */ |
这里的 iter() 用于创建集合的不可变引用迭代器,让你在不获取所有权的情况下遍历元素。这里由于 a 数组的元素都是可 Copy 的,不用 “.iter()” 也可以运行。
loop 循环
Warning:不要乱尝试 loop 的错误代码,无限循环可能会使电脑死机!!
loop 就是一个简单的无限循环,你可以在内部实现逻辑通过 break 关键字来控制循环何时结束。
例:
1 | fn main() { |
以上代码当 counter 递增到 10 时,就会通过 break 返回一个 counter * 2 的值,最后赋给 result并打印出来。
注:
- break 可以单独使用,也可以带一个返回值,有些类似 return
- loop 是一个表达式,因此可以返回一个值
模式匹配
模式匹配的含义
一个数据结构与一个模式进行比对,如果数据结构的形状和模式中指定的形状一致,则匹配成功,并且可以绑定模式中指定的变量到数据结构的相应部分。
核心要素:
- 结构比对而非值的比较
- 拥有解构能力(如复合数据类型中的组成部分,枚举类型的关联值)
- 有穷尽性检查
match、if let 和 maches!
match 语法
1 | match target { |
match 和其他语言的 switch 很像,_ 类似于 switch 中的 default 。
例:
match 语句块不作为表达式赋值:
1 | enum Direction { |
运行结果:
1 | South or North |
match 语句块作为表达式赋值:
1 | enum IpAddr { |
运行结果:
1 | ::1 |
模式绑定
模式匹配的另外一个重要功能是从模式中取出绑定的值
1 | enum Action { // 直接将数据信息关联到枚举成员,可以复习一下枚举的用法 |
运行结果:
1 | Hello Rust |
穷尽匹配
match 的匹配必须穷尽所有情况,所以下列代码会报错:
1 | enum Direction { |
_ 通配符
如果不想在匹配时列出所有值,可以像如下代码一样处理遗漏情况:
1 | let some_u8_value = 0u8; |
通过将 _ 其放置于其他分支后,_ 将会匹配所有遗漏的值。() 表示返回单元类型与所有分支返回值的类型相同,所以当匹配到 _ 后,什么也不会发生。
除了_ 通配符,用一个变量来承载其他情况也是可以的。
1 |
|
if let 匹配
当你只要匹配一个条件,且忽略其他条件时就用 if let ,否则都用 match。
以下两种代码等效:
1 | /* 1 */ |
if 和 if let 的区别:if 用于基于布尔表达式的条件分支;if let 用于基于模式匹配的条件分支,主要用于处理枚举等可匹配的类型,并能将匹配到的值绑定到变量。
matches! 宏
Rust 标准库中提供了一个非常实用的宏:matches! ,它可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
基本匹配:
1 | let value = Some(5); |
匹配枚举变体:
1 | enum Status { |
使用通配符:
1 | let value = Some("hello"); |
变量遮蔽
无论是 match 还是 if let,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
1 | fn main() { |
运行结果:
1 | 在匹配前,age是Some(30) |
需要注意的是,match 中的变量遮蔽其实不是那么的容易看出,因此要小心!其实这里最好不要使用同名,避免难以理解。
忽略模式中的值
有时忽略模式中的一些值是很有用的,比如在 match 中的最后一个分支使用 _ 模式匹配所有剩余的值。 你也可以在另一个模式中使用 _ 模式,使用一个以下划线开始的名称,或者使用 .. 忽略所剩部分的值。
使用
_忽略整个值1
2
3
4
5
6
7fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {}", y);
}
fn main() {
foo(3, 4);
}这样的代码不使用函数参数 x 不会报错“存在未使用的函数参数”。
使用嵌套的
_忽略部分值1
2
3
4
5
6
7
8
9
10
11
12
13let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {:?}", setting_value);这段代码会打印出 Can’t overwrite an existing customized value 接着是 setting is Some(5)。
第一个匹配分支,我们不关心里面的值,只关心元组中两个元素的类型,因此对于 Some 中的值,直接进行忽略。 剩下的形如
(Some(_),None),(None, Some(_)), (None,None)形式,都由第二个分支_进行分配。还可以在一个模式用多处下划线忽略特定值:
1
2
3
4
5
6
7let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {}, {}, {}", first, third, fifth)
},
}这会打印出 Some numbers: 2, 8, 32, 值 4 和 16 会被忽略。
使用下划线开头忽略未使用的变量(_x)
注意, 只使用_和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。1
2
3
4
5
6
7let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s); // 所有权已经失去,这里会报错1
2
3
4
5
6
7let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{:?}", s); // 所有权不会失去,s 没有被移进 _用
..忽略剩余值1
2
3
4
5
6
7
8
9
10
11struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {}", x),
}对于有多个部分的值,可以使用
..语法来只使用部分值而忽略其它值,这样也不用再为每一个被忽略的值都单独列出下划线。..模式会忽略模式中剩余的任何没有显式匹配的值部分。这里列出了 x 值,接着使用了
..模式来忽略其它字段,这样的写法要比一一列出其它字段,然后用_忽略简洁的多。还可以用
..来忽略元组中间的某些值:1
2
3
4
5
6
7
8
9fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {}, {}", first, last);
},
}
}这里用 first 和 last 来匹配第一个和最后一个值。
..将匹配并忽略中间的所有值。然而使用
..必须是无歧义的。如果期望匹配和忽略的值是不明确的,Rust 会报错。下面代码展示了一个带有歧义的..例子,因此不能编译:1
2
3
4
5
6
7
8
9fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {}", second)
},
}
}
解构 Option
回顾一下“复合类型(二)”——枚举(在上一篇文章里)的 Option 枚举:
1 | enum Option<T> { |
简单解释就是:一个变量要么有值:Some(T),要么为空:None。
使用 Option<T>,是为了从 Some 中取出其内部的 T 值以及处理没有值的情况
下面的函数实现的功能为:获取一个 Option<i32> ,如果其中含有一个值,将其加一;如果其中没有值,则函数返回 None 值
1 | fn plus_one(x: Option<i32>) -> Option<i32> { |
plus_one 接受一个 Option<i32> 类型的参数,同时返回一个 Option<i32> 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 None ,则返回一个 None 且不做任何处理;如果传入的是一个 Some(i32),则通过模式绑定,把其中的值绑定到变量 i 上,然后返回 i+1 的值,同时用 Some 进行包裹。
模式适用场景
模式
模式是 Rust 中的特殊语法,它用来匹配类型中的结构和数据,它往往和 match 表达式联用,以实现强大的模式匹配能力。模式一般由以下内容组合而成:
- 字面值
- 解构的数组、枚举、结构体或者元组
- 变量
- 通配符
- 占位符
所有可能用到模式的地方
match
1
2
3
4
5match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
_ => EXPRESSION,
}match 的每个分支就是一个模式,因为 match 匹配是穷尽式的,因此我们往往需要一个特殊的模式
_,来匹配剩余的所有情况if let
1
2
3if let PATTERN = SOME_VALUE {
}if let 往往用于匹配一个模式,而忽略剩下的所有模式的场景
while let
1
2
3
4
5
6
7
8
9
10
11
12// Vec是动态数组
let mut stack = Vec::new();
// 向数组尾部插入元素
stack.push(1);
stack.push(2);
stack.push(3);
// stack.pop从数组尾部弹出元素
while let Some(top) = stack.pop() {
println!("{}", top);
}一个与 if let 类似的结构是 while let 条件循环,它允许只要模式匹配就一直进行 while 循环。
这个例子会打印出 3、2 接着是 1。pop 方法取出动态数组的最后一个元素并返回 Some(value),如果动态数组是空的,将返回 None,对于 while 来说,只要 pop 返回 Some 就会一直不停的循环。一旦其返回 None,while 循环停止。我们可以使用 while let 来弹出栈中的每一个元素。
你也可以用 loop + if let 或者 match 来实现这个功能,但是会更加啰嗦。
for 循环
1
2
3
4
5let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{} is at index {}", value, index);
}这里使用 enumerate 方法产生一个迭代器,该迭代器每次迭代会返回一个 (索引,值) 形式的元组,然后用 (index,value) 来匹配。
let 语句
1
2let x = 5;
let (x, y, z) = (1, 2, 3);这其中,x 也是一种模式绑定,代表将匹配的值绑定到变量 x 上。因此,在 Rust 中,变量名也是一种模式。同理,一个元组也可以与模式进行匹配。
let 解构结构体的一些方式(均合法):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38/* 1 */
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}
/* 2 */
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}
/* 3 */
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {}", x),
Point { x: 0, y } => println!("On the y axis at {}", y),
Point { x, y } => println!("On neither axis: ({}, {})", x, y),
}
}函数参数
1
2
3
4
5
6
7
8fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({}, {})", x, y);
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}函数参数也是模式,上述的 &(x, y) 就是一个模式,&(3, 5) 会匹配模式 &(x, y),因此 x 得到了 3,y 得到了 5
let-else 匹配
1
2
3
4
5
6
7/* 1 (会报错) */
let Some(x) = some_option_value;
/* 2 (不会报错) */
if let Some(x) = some_option_value {
println!("{}", x);
}- 对于 let,因为右边的值可能不为 Some,而是 None,这种时候就不能进行匹配,也就是上面的代码遗漏了 None的匹配。
- 对于 if let,因为 if let 允许匹配一种模式,而忽略其余的模式(可驳模式匹配),所以不会报错。
为了让 let 变为可驳模式,Rust 1.65 新增了 let-else 匹配。它可以使用 else 分支来处理模式不匹配的情况,但是 else 分支中必须用发散的代码块处理(例如:break、return、panic)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15fn get_number(s: &str) -> Result<i32, String> {
// 尝试将字符串解析为数字,若失败则返回错误
let Ok(num) = s.parse::<i32>() else {
return Err(format!("'{}' 不是有效数字", s));
};
// 若解析成功,继续使用 num
println!("解析到的数字是: {}", num);
Ok(num)
}
fn main() {
let result = get_number("42"); // 成功:解析到的数字是: 42
let error = get_number("abc"); // 失败:返回错误信息
}其中
parse::<i32>()是 Rust 中一个非常常用的方法,它的核心作用就是将一个字符串(&str 或 String)解析成 32 位有符号整数(i32 类型)。与 match 和 if let 相比,let-else 的一个显著特点在于其解包成功时所创建的变量具有更广的作用域。在 let-else 语句中,成功匹配后的变量不再仅限于特定分支内使用:
1
2
3
4
5
6
7
8// if let
if let Some(x) = some_option_value {
println!("{}", x);
}
// let-else
let Some(x) = some_option_value else { return; }
println!("{}", x);在上面的例子中,if let 写法里的 x 只能在 if 分支内使用,而 let-else 写法里的 x 则可以在 let 之外使用。
匹配守卫
匹配守卫(match guard)是一个位于 match 分支模式之后的额外 if 条件,它能为分支模式提供更进一步的匹配条件。
1 | let num = Some(4); |
这个例子会打印出 less than five: 4。当 num 与模式中第一个分支匹配时,Some(4) 可以与 Some(x) 匹配,接着匹配守卫检查 x 值是否小于 5,因为 4 小于 5,所以第一个分支被选择。
相反如果 num 为 Some(10),因为 10 不小于 5 ,所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,因为这里没有匹配守卫所以会匹配任何 Some 成员。
也可以在匹配守卫中使用 或 运算符 | 来指定多个模式,同时匹配守卫的条件会作用于所有的模式。
1 | let x = 4; |
@绑定
@(读作 at)运算符允许为一个字段绑定另外一个变量。当你既想要限定分支范围,又想要使用分支的变量时,就可以用 @ 来绑定到一个新的变量上,实现想要的功能。
1 | enum Message { |
运行结果为:
1 | Found an id in range: 5 |
上例会打印出 Found an id in range: 5。通过在 3..=7 之前指定 id_variable @,我们捕获了任何匹配此范围的值并同时将该值绑定到变量 id_variable 上。
第二个分支只在模式中指定了一个范围,id 字段的值可以是 10、11 或 12,不过这个模式的代码并不知情也不能使用 id 字段中的值,因为没有将 id 值保存进一个变量。
最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量 id,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对 id 字段的值进行测试:任何值都会匹配此分支。
Rust 1.56 新增:使用 @ 还可以在绑定新变量的同时,对目标进行解构:
1 |
|
Rust 1.53 新增:num @ (1 | 2) 型写法:
1 | fn main() { |
注意:无论哪种版本,num @ 1 | 2 都是不被允许的,因为编译器会解析成 (num @ 1) | 2 ,如此一来,num 没有绑定到所有的模式上,只绑定了模式 1。
方法 Method
定义方法
1 | struct Circle { |
注:上面的关联函数的调用只能用 :: 。例如: let cir = Circle::new(3, 3, 5);
Rust 中有一个约定俗成的规则,使用 new 来作为构造器的名称,出于设计上的考虑,Rust 特地没有用 new 作为关键字。
在之前的代码中,我们已经多次使用过关联函数,例如 String::from,用于创建一个动态字符串。
Rust 的方法区别于其他代码:
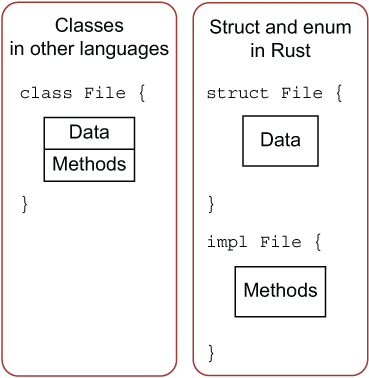
可以看出,其它语言中所有定义都在 class 中,但是 Rust 的对象定义和方法定义是分离的,这种数据和使用分离的方式,会给予使用者极高的灵活度。
方法的使用案例:
1 |
|
该例子定义了一个 Rectangle 结构体,并且在其上定义了一个访问器和 area 方法,用于计算该矩形的面积。
访问器的作用:直接访问 rect1.width 是不被允许的,因为 width 是私有的。此时只能用访问器获取。
impl Rectangle {} 表示为 Rectangle 实现方法( impl 是实现 implementation 的缩写),这样的写法表明 impl 语句块中的一切都是跟 Rectangle 相关联的。
self、&self 和 &mut self
在 area 的签名中,我们使用 &self 替代 rectangle: &Rectangle,&self 其实是 self: &Self 的简写(注意大小写)。在一个 impl 块内,Self 指代被实现方法的结构体类型,self 指代此类型的实例,换句话说,self 指代的是 Rectangle 结构体实例,这样的写法会让我们的代码简洁很多,而且非常便于理解:我们为哪个结构体实现方法,那么 self 就是指代哪个结构体的实例。
需要注意的是,self 依然有所有权的概念:
- self 表示 Rectangle 的所有权转移到该方法中,这种形式用的较少
- &self 表示该方法对 Rectangle 的不可变借用
- &mut self 表示可变借用
总之,self 的使用就跟函数参数一样,要严格遵守 Rust 的所有权规则。
回到上面的例子中,选择 &self 的理由跟在函数中使用 &Rectangle 是相同的:我们并不想获取所有权,也无需去改变它,只是希望能够读取结构体中的数据。如果想要在方法中去改变当前的结构体,需要将第一个参数改为 &mut self 。仅仅通过使用 self 作为第一个参数来使方法获取实例的所有权是很少见的,这种使用方式往往用于把当前的对象转成另外一个对象时使用,转换完后,就不再关注之前的对象,且可以防止对之前对象的误调用。
简单总结下,使用方法代替函数有以下好处:
- 不用在函数签名中重复书写 self 对应的类型
- 代码的组织性和内聚性更强,对于代码维护和阅读来说,好处巨大
带有多个参数的方法
1 | impl Rectangle { |
为枚举实现方法
1 |
|





